After a hack, should an organization restore its servers from a new OS or from the backup?
We were recently helping a hacked organization and this question was asked. The organization had been given two very different opinions, and wanted to know what we would do. The recommendations they had received came from two polar opposite ends of the spectrum.
One group said, “yes, absolutely, you must use a new OS and migrate the data,” while others said, “you’ll be fine to restore from a backup, just be sure the patch the vulnerability.”
Our response was a bit different – it depends.
This post expands on why our recommendation could be perceived to be ambiguous, but hopefully provides a framework that you can leverage when your organization is presented with the same question.
Balance Security Recommendations with Business Needs
To understand the recommendation, you need context:
This was a decent sized business with close to 100 servers compromised. The bad actor was able to deploy ransomware, and was holding the organization hostage for a ransom. These servers were the core of the company, it included all business functions (e.g., HR, Finance, R&D, Operations, Marketing, Commerce). The specific size in terms of head count, or revenue, doesn’t matter, but it’s important to note that they did not have a dedicated security team (but there did exist a person whose part-time job was security) and lacked basic security knowledge.
What we learned through the process is that the organization had no way of knowing a) the vector used to exploit the environment, or b) when the attack actually started.
What this tell us is that you have to assume worst-case, and worst case would undeniably require you to start with fresh OS installs. The problem, however, is can the business support a move like this?
This reminds us of our jobs as a security professional; we exist to help the organization achieve its business objectives, not the other way around. We help organization identify risk, and help implement controls to help mitigate those risk so that the business can continue to do its work. Post-compromise, that objective doesn’t change, in fact it expands. We not only have to identify and eradicate the issue, but also have a responsibility to ensure business continuity.
To appropriately give an answer on what needs to be done, you have to understand some very basic facts about an organization:
- Does the organization have a security team?
- Does the organization have a team required to spin up the new environment?
- Does the organization have the technical expertise?
- What are the specific configurations difference between the old environment and new environment?
- What kind of servers are we talking about?
- How long would it take (in hours / days)?
- What is the real confidence level of the estimate?
- Can the business afford to be down the projected time frame?
We have yet to meet an organization that meets these criteria that has had solid answers to any of these questions. And so, how you approach the problem must take these insights into consideration.
There is what they must do, and then there is what they can do. Our job in security is to help figure out the “how”.
Concepts That Establish a Foundation
An organization is often unable to answer the most basic questions post-compromise. This means that, while we can all agree that the desired end state should be fresh OS installs, the big variable we need to account for is time.
In a deployment like the one this organization was in, what is needed is a practical, phased, approach to how, and when, they go live. Which is why our recommendation was more grey than black and white.
The recommendation we provided was that they wanted to do both, but in a phased manner and it was built on three concepts:
| Categorization | A basic process of putting things into “categories” “groups” “classes” or some other similar bucket. |
| Functional Isolation | Stems from the world of electrical circuitry where you isolate components. We use it when talking about networks and systems to represent the same thing – isolate the function of a network, isolate the function of a server (i.e., a web server shouldn’t be print server, shouldn’t be an email server, let it serve one function). |
| System Boundaries | This is a term used in system design meant to represent the logical lines (“boundaries”) that help separate different environments. |
The biggest issue the organization is faced with is it doesn’t know how the attack happened.
In hindsight, they were able to identify a series of Indicators of Compromise (IoC) that pre-date the actual hack by a couple of weeks. This conforms to what we know of the tactics, techniques and procedures (TTPs) employed by bad actors, but falls short of providing a definitive answer around what happened. The organization is also limited in their forensic ability, it lacked any logging / activity tracking, and their backups were part of the compromised servers. Each of these contributes to the general consensus, that yes, they do want fresh OS installs.
It forces you to assume worst-case. But the business has a need to get operational, quickly, ensuring business continuity. This is where you must balance desired end-state with reality, learning to balance security with the business needs.
Fortunately, security professionals can help mitigate the risk.
Mitigating Exposure
The number one risk the organization must be aware of is that they might suffer a compromise the minute they spin back up. Bad actors are known to deploy their payloads within a network that allow them to bypass access mechanisms and defensive controls. This is the reality you must deal with when you don’t know how a hack happened.
As such, your focus is not so much about preventing the hack but reducing the potential impact if, when, it happens again.
This can be mitigated by using a phased approach, one in which they establish new system boundaries that are functionally isolated and based on a hierarchical categorization scheme.
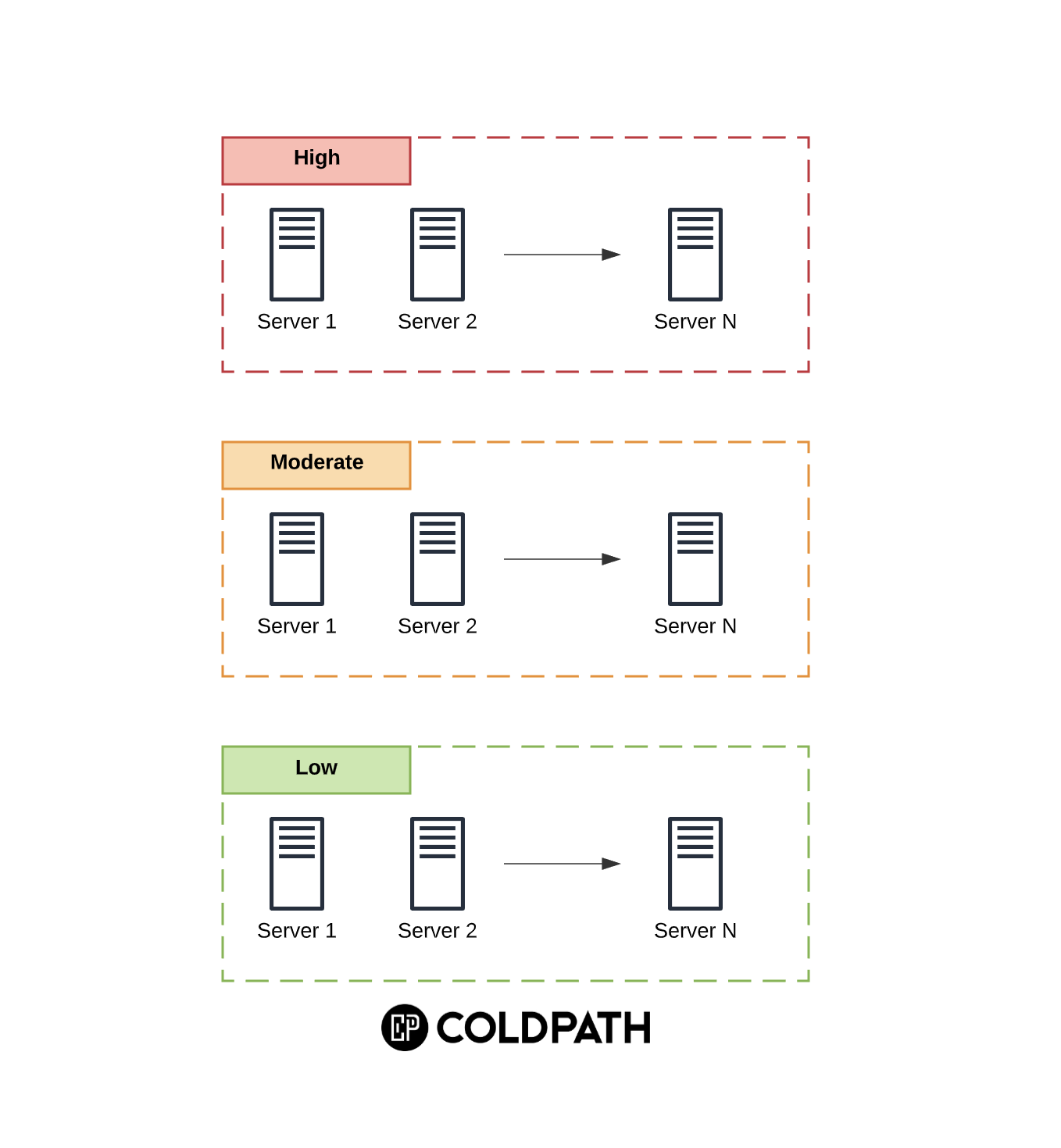
1. Categorize the Servers
Servers should be categorized based on their impact to the business.
A well recognized categorization scheme is: Low (L), Moderate (M) and High (H).
The most difficult part of this process is assessing what belong in what category. The following calculation should be employed:
Security Category (SC) =
{(confidentiality, impact), (integrity, impact), (availability, impact)}
This model makes use of the security triad – Confidentiality, Integrity and Availability (CIA) that speaks to the three core security objectives
Example of how it can be applied:
A department file server contains both sensitive personnel information and routine administrative information. The following are possible security categories for the information on the file server.
SC personnel information =
{(confidentiality, M), (integrity, M), (availability, L)}
SC administrative information =
{(confidentiality, L), (integrity, L), (availability, L)
The resulting categorization of the file server would be the highest level of categorization for each type of information or data on it.
SC file server =
{(confidentiality, M), (integrity, M), (availability, L)}
Which would mean that the file server is categorized as Moderate.
This is probably the most consuming part of the process.
2. Reduce Function Where Possible
The categorization process should shed light on what each server is doing. This is an opportunity to identify those that should be repurposed to reduce its functionality where possible, i.e., system functional isolation.
3. Establish New Boundaries
Once you have your servers categorized, you can establish new system boundaries. These boundaries are basic logical groupings of each category and help you better understand your environment.
4. Isolate System Boundaries
Once you have those boundaries, you must take the time to perform two critical functions (i.e., network functional isolation):
- Review access controls;
- Review user groups;
The biggest mistake organizations make that allow for this level of compromise is a systematic failure of how roles, the associated responsibilities, and access are managed.
The new server categories present an opportunity to review how its roles / responsibilities are designed and implemented. It should force you to ask tough questions around who needs access to what systems. It should also force you to asses how information flows between the various system boundaries.
A basic construct would ensure that communication between systems is not allowed across different levels at a minimum, but should introduce additional controls (e.g., firewalls, access constraints, MFA) within boundaries as well.
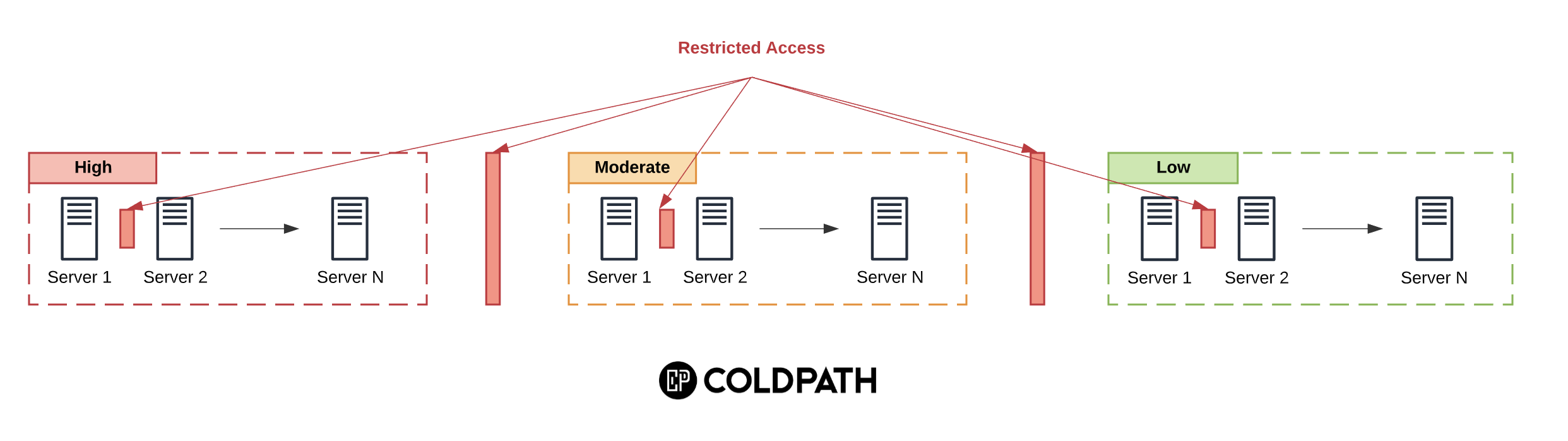
This is also a great time to spend time on access control itself. What level of authentication is being employed?
The more critical a system, the important it is to ensure appropriate checks and balances are introduced. This is where things like Multi-Factor Authentication (MFA) become extremely important. If you’re interested to learn more about MFA, I encourage you to read the series of articles prepared by my friend Jesper Johansson on the subject.
5. Phased Deployment
The first three steps help you design and implement a plan of action based on the first four steps of this process.
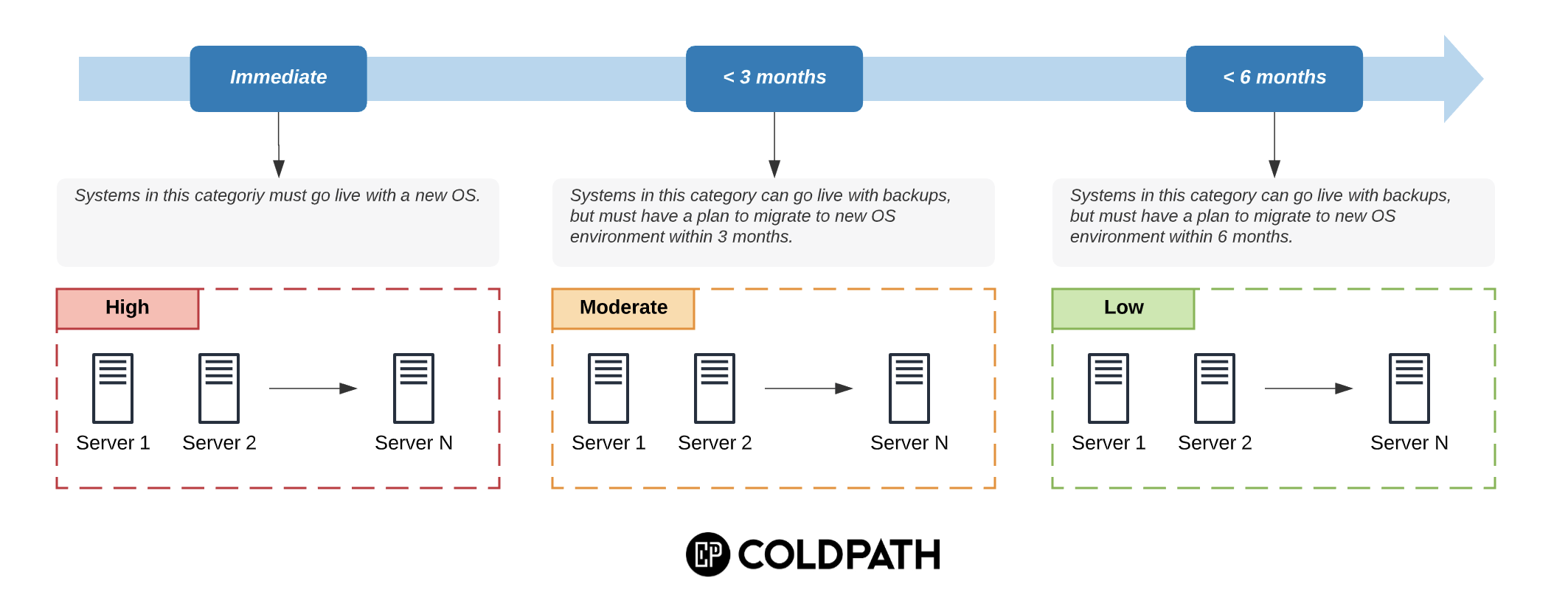
This approach highlights the sequencing of events. It identifies how specific environments should go live.
Servers that are deemed critical, based on your categorization calculation, should not go live with a new OS, while those that are deemed less impactful to the business have the ability to go live with backups.
This approach provides your business a very practical system that helps balance the potential risk and the need for business continuity.
Working in a World of Unknowns
As security professionals the business does not serve us, we serve it. We must educate and inform those responsible for the business, and it’s our responsibility to adapt and help come up with creative solutions that help align to the ultimate objective – run the business.
We must not be rigid in our thinking, instead we should tailor our ideas accordingly. In the world of security we will rarely have enough information.
The scenario above helps illustrate what this means.
Both consultants were right in the desired outcomes, but wrong in the absolute nature of the proposed sequence of events. Taking into consideration the full scope of the compromise, and state of the business, helps us create unique approaches that helps achieve the same outcome over a period of time, while also helping to reduce the risk of a new compromise.
When we work in a world of unknowns all we can do is make the best possible decisions under the current circumstances.